
A Survey of Visual Attention Mechanisms in Deep Learning
Visual attention is so much a part of everyday life that most people never stop to think about why, or how, it happens. Focusing on the road while you’re driving, glancing at the food on your plate before you take a bite, looking at the text instead of the sidebars or screen bezel when you’re reading, attention is an obvious fact of life. Why look at the screen instead of around the whole room when someone asks you whether it’s Matt Damon or Mark Wahlberg in the movie?

However, when we’re training a neural network, we need a way for it to explicitly incorporate the concept of visual attention. It needs to be able to learn, for example, that the most important place to look in order to make distinctions between actors is their facial features, instead of their shoes or the large popcorn bucket you ashamedly ate most of.
We should make such a mechanism trainable, so that given a task and a set of images relevant to it, the network starts to learn to “filter out” irrelevant sections of the image to make clearer and more robust judgements for the task.
Well, with the hoard of deep learning researchers that have materialized in the past decade we can be sure that at least a few hundred of them have realized this might be the secret sauce to wring a few more drops of performance out of ImageNet (and become king of the SOTA pile). Joking aside, there is a large amount to be gained from a method that allows our models to focus their computations and understand what’s relevant.
Enter attention mechanisms: these will endow our networks with this ability and make them more interpretable, robust, and performant. We start with a definition of attention, review several noteworthy papers in visual attention over the last decade, and along the way observe how these methods achieve impressive and sometimes mind-blowing results on image classification, understanding, and generation tasks. We assume an intermediate knowledge of convolutional neural networks, recurrent neural networks, and overall network design principles. Let’s get started:
Table of Contents:
<> What is attention?
<> Visual glimpses and Reinforcement Learning
<> Hard vs. Soft Attention
<> Show, Attend and Tell: Neural Image Captioning
<> Convolutions Everywhere
<> Learn to Pay Attention
<> Transforming the Way Attention Works
<> Conclusion
What is Attention?
Attention is a difficult term to explicitly define in the deep learning literature — broadly it applies to a mechanism by which a network can weigh features by level of importance to a task, and use this weighting to help achieve the task. The latter portion is important to help distinguish from feature importance methods, which are often calculated after a model is trained and used to interpret a model’s predictions (such as class activation maps or activation atlases) and generally don’t serve to improve performance or reduce computation like trainable attention methods do. Attention models are widespread among multiple areas of deep learning, and the learned weighting schemes can apply to features as diverse as pixels in an image, words in a sentence, nodes in a graph, or even points in a 3D point cloud.
The idea of attention was born in the area of seq2seq modeling, where models are trained to consume a sequence of arbitrary length (such as an English sentence) and output another sequences, also of arbitrary length (such as the same sentence in Spanish). The issue with such tasks is that there is often a complicated dependency that ranges far beyond the last sequence element seen, and such a dependency can vary between input sequences. There emerges a need to learn a flexible dependency mechanism that, given an input sequence, can figure out which sequence elements are most important to constructing an accurate output sequence. However, this kind of dependency is also important in computer vision tasks, where instead of the dependency being along the time domain it is along the spatial domain. The same texture may be present in multiple areas of an image, multiple disjoint semantic cues may give clues to the overall classification of an image, and an object may have multiple complex and obscured parts throughout an image.

Being able to learn these dependencies beyond the limited receptive field of a convolutional filter is important in capturing maximum performance and allowing our models to build a wider intuition, and several researchers have tackled this challenge in different ways.
Visual Glimpses and Reinforcement Learning
The first paper we will look at is from Google’s DeepMind team: “ Recurrent Models of Visual Attention” (Mnih et al., 2014). This paper focuses on the idea that CNN architectures utilize a sliding window approach (iterating convolution filters over the extent of the image) whereas humans only process areas of an image most relevant to a given task. The authors embrace the idea of vision as fundamentally a sequential task, where portions of an image are “glimpsed” in sequence to help achieve a particular task. There are a few existing papers that take this approach, including this excellent older paper “ A Reinforcement Learning Model of Selective Visual Attention” (Minut, Mahadevan, 2001), where the task is fixed at finding a particular pre-defined object in a scene and reinforcement learning is used to optimize the visual search.

However the DeepMind paper expands this to arbitrary tasks by utilizing reinforcement learning directly for the task. They incorporate the “glimpse sensor” — a function that takes in an input image and a location on that input image, then outputs a “retina-like” representation of the pixels in that location. This representation consists of multiple resolution scales centered at the area.
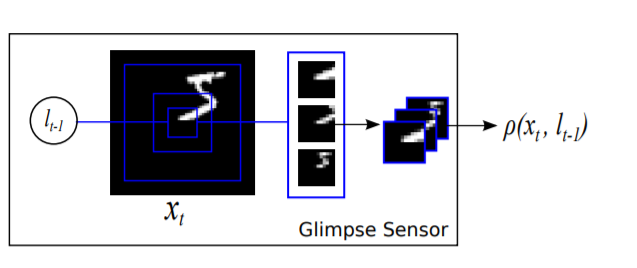
The location of the glimpse along with the retina-like representation of the image at the glimpse is then combined into a single vector embedding — this embedding is used to predict which location to glimpse at and the corresponding action/classification. For object detection this action/classification might be whether the glimpse contains an object or not, for a video game it might be how many points are scored during that glimpse, either way the reward signal is propagated backwards to better choose glimpse locations and corresponding actions/classifications via the glimpse network.
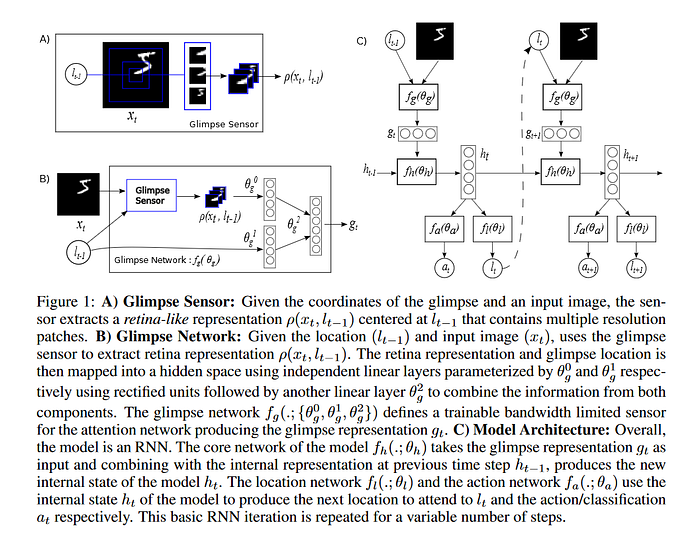
The performance is respectable on MNIST and MNIST with translations and noise (as chunks of other MNIST characters) added.

Because the model is not differentiable end to end (see the hard vs. soft attention section below) it must be trained with an algorithm called REINFORCE. The combination of the RNN having to learn both next position and action/classification and the instability of the REINFORCE algorithm can make this model hard to train, however it is one of the few excellent models of hard attention and achieves an impressive performance with relatively little computation.
Soft vs. Hard Attention
Before we look at some more papers it is important to address the distinction between “hard” and “soft” attention mechanisms. The simplest way to think about this is by imagining looking through a a foggy pane of glass vs. looking through binoculars.

Looking through a foggy pane of glass represents soft attention, where the entire image is still being “seen”, but certain areas are being attended to more. Whereas the binoculars represent hard attention, where we are only seeing a subset of the image, hopefully the part most relevant to our task. The Recurrent Models of Visual Attention paper from above represents hard attention. The key thing to take away is that there are explicit trade-offs between these attention types: hard attention requires significantly less computation and memory (as the entire image is not being stored or operated over usually) but cannot be easily trained as the objective is non-differentiable (there is no gradient, pixels are either seen or unseen). Hence it is often trained with methods like REINFORCE. Soft attention on the other hand often requires more memory and computation (often even more then simple convolutional nets) but has a differentiable objective and can be easily trained with standard back propagation methods.
Show, Attend, and Tell: Neural Image Captioning
The next paper we will look at integrates both hard and soft attention and a comparison between them. “ Show, Attend and Tell: Neural Image Caption Generation with Visual Attention” (Xu et al. 2015) is a paper out of the universities of Montreal and Toronto that uses attention to attack one of the critical problems in the computer vision area — image captioning. This is the problem of being able to generate a sensible caption (in natural language) given an image, and is critical to teaching computers about image understanding.

The authors use an encoder-decoder architecture, where the decoder is outfitted with an attention mechanism. The encoder is a CNN, where features are extracted from a convolutional layer, which allows the attention in the decoder to focus on spatially relevent portions of the input image. The decoder uses it’s previous hidden state, the previously generated word, and a “context” vector to generate the next word of the caption.
This “context” vector is where attention comes in, it is calculated from the CNN output features of the encoder and represents a positive weight for each spatial location of the encoder’s output. This weight is calculated with an “attention” function, which can be formulated in different ways leading to the hard and soft attention variants.
For hard attention, the spatial location of interest (coded as 0,1 for hard attention) can be parameterized by a Multinouli distribution and optimized using the log-likelihood (intuitively representing the probability of seeing a sequence of words given a portion of the image) via a learning rule similar to REINFORCE.
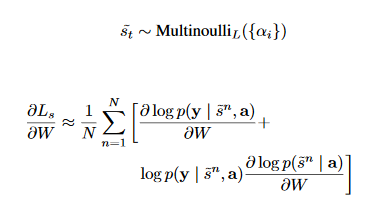
For soft attention, since the weights are real values we can directly maximize the marginal likelihood over all possible attention locations and train directly with back propagation (the authors also use a regularization term to encourage the attention area from taking very high providence and forcing the decoder to inspect the rest of the image as well).
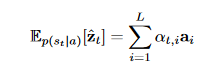
For some images both hard and soft attention produce the same captions but with different attention areas (soft attention above, hard attention below):

To get around the issue of varying caption lengths, at each mini-batch a sequence length was specified and only captions of that length were drawn. The training converged in approximately 3 days on a Titan Black GPU, and the results were cutting edge at the time (in terms of BLEU score). The soft attention model also agreed strongly with human intuition, below are some words and the corresponding spatial location weighted by attention during caption generation:

Convolutions Everywhere
Another approach to integrating attention that has become popular deals with reformulating the idea of image convolutions themselves. “Non-local Neural Networks” (Wang et al. 2017) is a paper out of Carnegie Mellon and Facebook Research that tries to deal with the local receptive field of convolution operations. Traditionally, “long-distance dependencies are modeled by the large receptive fields formed by deep stacks of convolutional operations”. Doing things this way forces inefficient computations, makes optimization difficult (via exploding and vanishing gradient issues), and can make modeling multi-hop dependencies (where multiple disjoint areas need to be revisited to determine action, such as with videos) difficult. The paper argues that making the convolutional operator “global”, they can avoid excessively deep networks and improve performance (though the operator by itself would be more computationally expensive then a local convolution). Implicitly, this uses self-attention, a topic we will make explicit in a later section.
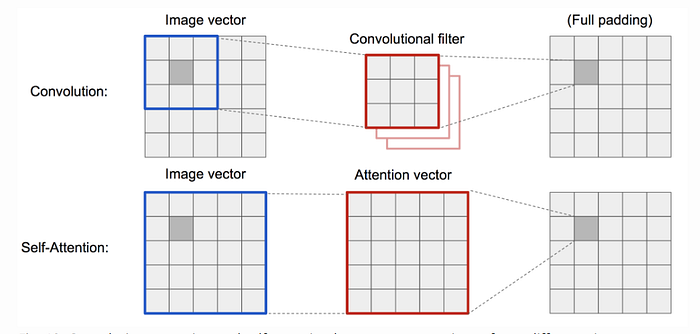
The non-local convolutional operation is formulated as:
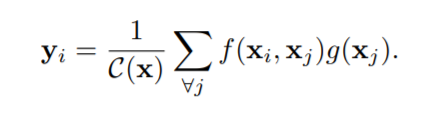
Where i is the index of an output position (in space, time, or spacetime) whose response is to be computed, and j is the index that enumerates all possible positions. x is the input signal (image, sequence, video; often their features) and y is the output signal of the same size as x.
A pairwise function f computes a scalar (representing relationship such as affinity) between i and all j. The unary function g computes a representation of the input signal at the position j. The response is normalized by a factor C(x). Note that this is a global operation since for a given spatial position i, the response depends on all other spatial positions j. All the values are real numbers, and the whole thing can be optimized through back propagation and included at any point in a traditional network.
The authors only consider g(x) as a linear embedding (multiplication by a single scalar) implemented as a 1D convolution. For the function f they consider a few different options, including the Gaussian function (we can also replace each x position here with an embedded version):
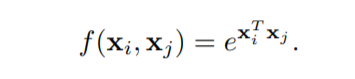
The dot-product in an embedded space of each x:
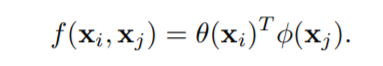
And a concatenation operation (denoted by square brackets) in an embedded space, along with an induced non-linearity:

Note this last function is described in length in “A Simple Neural Network Module for Visual Reasoning” (Santoro et al. 2017). Finally, if we consider the non-local operation as a whole (the first equation in this section) as our y, we can denote the output of a non-local block as the following:
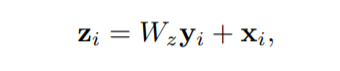
Summing with the input example x allows this to become a residual connection, so that if the weight matrix W is initialized to zero then the non-local block has no effect on the behavior of the network. This formulation is more expensive then traditional convolution, and the authors do sub-sampling of the signal (by pooling) and cutting the channel depth to half in the output in order to reduce computations by a factor of 6.
To visualize the network’s “attention”, the authors find the 20 highest weighted x_j for a given x_i position, and visualize these as arrows. They show these for videos from held out examples on the task of classifying human actions on the Kinetics dataset. The results are impressive, showing intuitive and meaningful relationships that would help to classify the target actions:

and there is marked improvement in training and validation behavior against a Resnet-50 baseline for the same task:
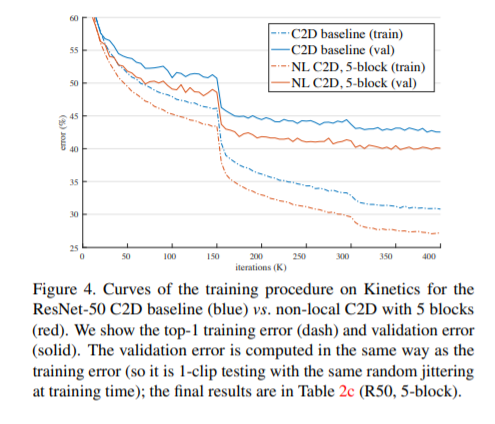
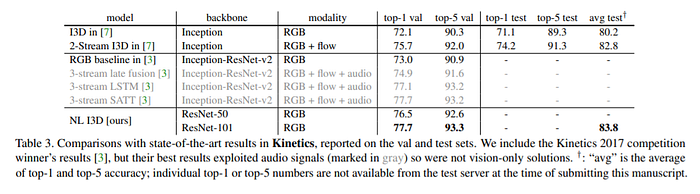
One argument is that these results are simply because the non-local block is mimicking increased depth in the network, however the authors note that adding it to Resnet-50 increases performance above the deeper Resnet-101 architecture (which has 30% more parameters and utilizes 20% more FLOPS then Resnet-50+Non-local block), and as such this is likely not the only candidate for performance increase. There was also no performance increase when the non-local block was substituted for a standard residual block.
Another benefit is that by concatenating time along the channel dimension (for videos), the non-local block can automatically capture dependencies spatial dependencies through time. The model performs better and is more efficient then simply using 3D convolutions, although they are complimentary when used together.
The long-range spatial dependencies learned by non-local blocks also turn out to be very useful in image generation, as used in the excellent paper “ Self-Attention Generative Adversarial Networks” (Zhang et al. 2018).
Learn to Pay Attention
So far we’ve studied attention mechanisms that treat vision as a sequential “glancing” problem, utilize word sequences to decide attention, and a reformulation of convolutions to include attention as a global weighting over the entire image/feature space. Now, we will look at a similar paper that aims to force a model to make attention as efficient as possible, by utilizing only the attention maps as the primary driver to a prediction (opposite to the function of the regularization term used in the previous neural captioning paper).
“Learn to Pay Attention” (Jetley et al. 2018) utilizes multiple intermediate feature maps and a similarity function to create a “global” image representation — a score matrix that is refined through the network and fed as a standalone input to produce the final classification. This is a strikingly simple and effective formulation of attention, and can be integrated with existing CNN architectures (even some of the ones we’ve seen already, such as non-local convolutions) to improve generalization ability and robustness to adversarial attack.
Consider the output of the first convolutional layer of a network, call this L. For now we will make the somewhat unrealistic assumption that Dim(L) = Dim(I), where I is the input image. We can use a similarity function S (a dot product for example) to calculate the relative score matrix for this layer: S(I, L). We can then immediately normalize this and feed it into a fully connected layer for classification. The idea here is that the network learns to tune the convolutional filter producing L so that when the dot product is taken between it and the input image I, the regions most important to an accurate prediction receive high scores (since only the resulting score matrix is used for classification). This is precisely the basic concept behind attention.
Two different similarity functions are considered in the paper, the basic dot product we thought about before (i is the layer index, s is the spatial index over the feature map):
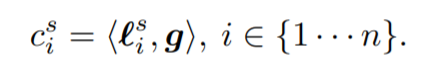
and a parameterized alignment function formulated for neural machine translation:
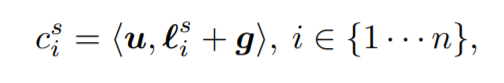
Which has an explicit alignment parameter to tune, u. Also notice the current feature map and global image are summed — this limits the number of resulting parameters for attention. In most of the experiments, the alignment function performs better then the dot product. This might be because the alignment parameter is able to learn more general concepts like object and space that apply to all image categories and further refine the attention map.
Removing the unrealistic assumption that the input image and convolution output are the same dimension, we note that the similarity function is not straightforward to compute with inputs of differing dimensions. The paper takes the stance that g should be downscaled to the size of the layer output (using a single layer neural network to produce the embedding). This again limits the size of the attention map.
Since we may implement this module at multiple points in the network, each of the attention maps can either be (a) concatenated together into a single vector and passed to the fully connected layer (b) passed into a unique fully connected (classification) layer for each map, the results of each of these averaged to get the final classification. In experiments option (a) seems to perform better, likely indicating that the raw feature maps preserve meaningful enough information that collapsing each into categorical probabilities is counter-productive.
Since the attention module emphasizes certain features towards the end task of classification, the authors recommend utilizing it towards the end of the network so the features used for each attention map are relatively “mature” (representing objects and areas of semantic importance instead of edges or gradations). Their implementation utilizing a VGG network looks like the following:
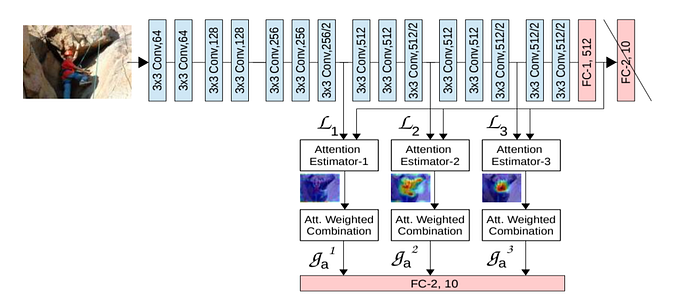
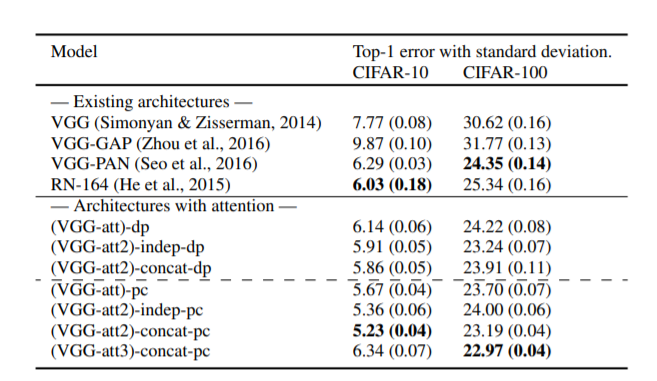
Where all 3 attention maps are concatenated and passed to the fully connected layer (FC-2, 10) for classification. The results are impressive against a Resnet-154 architecture on CIFAR-10 and CIFAR-100 datasets:
Even more impressive is the sharp attention maps produced by this technique when compared with an existing method (CIFAR-10):

Hence, these attention maps can be used for weakly supervised instance segmentation, a computer vision task where an object of interest must be segmented out based only on information that the image contains the object of interest (for example segmenting the actual truck out in an image labeled “truck”). The Object Discovery dataset is a good for this, and utilizing the attention maps for instance segmentation yields good results (values in terms of IoU score):

The lower values for the “Airplane” and “Horse” category might be explained by complex structural details (such as the horse’s legs) and small size, the authors explain.
The authors also explain how this method can be used to increase resilience to adversarial attacks.
Transforming the Way Attention Works
For this section, we will first take a whirlwind tour of a somewhat obscure formulation of the image generation problem that allows us to borrow the sophisticated attention models from seq2seq research directly.
We can think of the pixels in an image as being generated sequentially, i.e if we consider the first row of pixels, if we have the first 5 pixels we can utilize that information to guess the value of the 6th one. Taking all the rows of pixels and connecting them end-to-end we now have a very large sequence (height x width of the image long) and we can can talk about P(I), the probability of generating a particular sequence (corresponding to an image). If we take the stance that each pixel is dependent on the pixels before it and otherwise independent, we can formulate P(I)— the likelihood of generating a particular image, as follows:
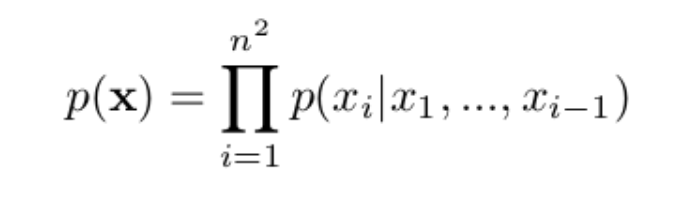
For each of the pixel probabilities, we can utilize an auto-regressive model like an LSTM to calculate them (a bit of technical detail here, this requires treating each pixel as a categorical variable on 0–255, thus the output of a softmax layer will be a 255 length vector indicating the probabilities of each pixel intensity). When we’re done we end up with a full posterior distribution for our output image and we can easily condition the calculation on a number of input vectors, such as the class of the image we want to generate, an image caption, or even the spatial locations of certain objects. These models are generative, and an alternative to the popular Generative Adverserial Networks, boasting increased training stability and an explicit posterior (though not always performing better).
Also, there are a number of other issues with this approach: there is no realistic reason why each pixel’s dependency would be so simplistic (only depending on the pixel or few pixels before it-as signal weakens over the length of the sequence), and generating an image pixel-by-pixel is extremely time consuming and not something that can be easily sped up by parallelization (since each pixel depends on previous ones already being generated).
Once again, CNN’s can help us out here. It may not be immediately clear how to turn our sequential image generation problem into one amendable to convolutions, but the ground breaking PixelCNN paper provides a clever solution: sequentially masking portion of the feature map after each convolution.
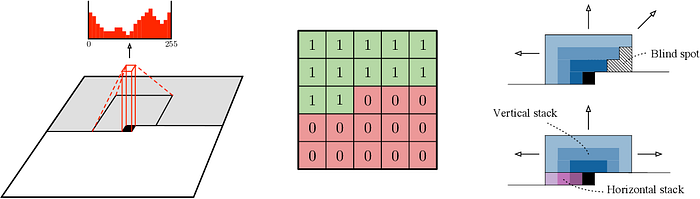
While this is a gross simplification of many of the fine details of the PixelRNN and PixelCNN papers, it will serve our purposes. This modification using convolutions makes it possible to speed up the computation significantly. While not as performant as PixelRNN, the decreased computation time and theoretical importance of this method make it important to know (for example the popular Wavenet architecture is based on PixelCNN).
The shortcomings in performance compared to PixelRNN are likely due to the power of the LSTM module in modeling long term dependencies (and also an effectively larger receptive field then PixelCNN-since all previous positions are considered and weighted appropriately). However, as powerful as the LSTM cell is in modeling these long term pixel dependencies, it is not perfect. The distance between an input token and and it’s output token grows proportionally to N, leading to long range dependencies being difficult to model, a problem not solved by adding plain attention (which also makes training even more expensive).
However, in our CNN formulation this distance grows proportionally to log(N), making neighboring (however not necessarily long range) dependencies much more tractable . Unlike an LSTM the receptive field grows in a rectangular fashion (vs. linearly in pixel order) and long range dependencies are not naturally “remembered” as with an LSTM, however the gated version of PixelCNN achieves 90% of the performance of PixelRNN with 50% of the training time. We can add one more ingredient to this CNN formulation that will boost its powers even further: self-attention.
The main idea of self attention is treating a sequence as a series of key-query pairs, an element being a query when it is the one being currently utilized in the task and a key when it is being paid attention during a different element’s usage.
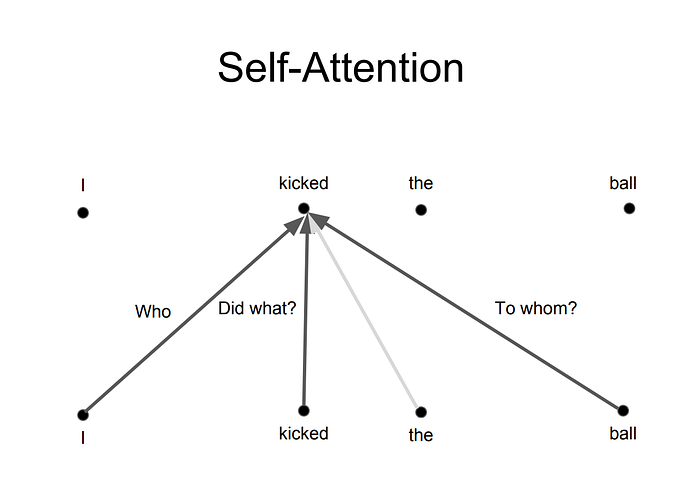
The way this is implemented is by learning query, key, and value (more on this one later) matrices to multiply each element by. This gives the model more freedom to model different dependencies for each element, for when that element is being actively translated and when that element is simply being paid attention to in relation to a different element. For a two element sequence we can model the entire calculation for the first element-multiplying its query by each of the keys (itself and the second word in this case), dividing to stabilize gradients, softmax, and multiplying by the value matrix to get a relative weighting.

Not exactly the simplest thing in the world, but it gives our model more meaningful parameters to learn long range dependencies and the strength of these dependencies. Importantly it allows the model to pay attention in context, when generating a nature scene a patch of grass may initially be important for placement of a tree, but may later become important for generating the canopy of the tree. Spicing this method up with multiple attention heads and positional encoding and you have the Transformer, illustrated here beautifully with flames:

Remember, the sequence elements in our case are not words but image pixels. Integrating the Transformer allows us to drop the LSTM and model long range pixel dependencies that may indicate the same texture on distant objects, cues about additional objects from certain semantic clues, and disconnected views of the same object. This is the innovation of the “Image Transformer” (Parmer, Vaswani et al. 2018), which makes important strides in a few different areas of image generation. A single layer of their architecture is below:

An important thing to note is the experiments with varying 1D and 2D queries and their corresponding key/memory blocks. Self-attention in general has a computation overhead of O(w*h*d*m) where w,h are the width and height of the image, d is the channel depth, and m is the number of memory locations to attend to. The authors make this tractable by localizing the self-attention mechanism to local neighborhoods of pixels around the query location:
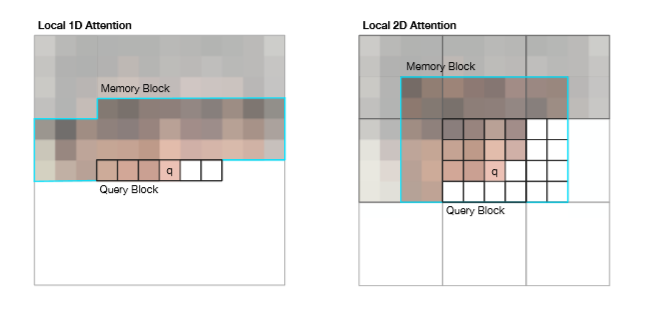
They note that the size of this receptive field is critical to performance, and may explain the differences between PixelRNN and PixelCNN. The localization of attention allows the authors to utilize a much bigger receptive field then PixelCNN. Because of the sequential pixel generation the model performs great on image completion tasks:

and the local attention also allows it to attain some mind blowing performance on super resolution/up-scaling tasks:

The authors close by noting that while auto-regressive generative models are usually thought of as an alternative to GAN’s, their integration (especially with the more computationally feasible locally restricted form of self-attention) into GAN architectures may lead to further improvements.
Conclusion
Throughout this article we’ve defined attention in a computable way (weighting input features by importance to a task, and utilizing this weighting to help accomplish the task) and learned about multiple ways of formulating this in a deep learning framework: training hard attention via RL, utilizing natural language captions to guide attention, formulating a global convolution operator, generating attention maps as the only signal for classification, and even generative models which treat images as pixel sequences and attend to different sequence positions.
We’ve observed impressive results using attention to improve performance on classification and super resolution tasks, image caption generation, and even performing object segmentation from only image-level labels.
There is no doubt that the additional parameters introduced by attention mechanisms can lead to more interpretable and performant models, but often at the cost of increased complexity (sometimes to a questionable degree). Increasing theoretical understanding and reducing computational complexity of attention mechanisms (to perhaps mimic human visual attention mechanisms which reduce cognitive load) are important research areas, as is integrating attention into different applied problems to improve performance. Overall, the focus on attention is changing the deep learning landscape and improved formulations and implementations will likely be a key feature in seminal papers to come.
(Obviously this article was a large undertaking in breadth, so please let me know if I’ve made any erroneous statements, misrepresented an idea, mis-cited a paper, or otherwise made an unforgivable grammatical error. Thank you for reading)
References
“Learning Deep Features for Discriminative Localization” (Zhou et al. 2016) — http://cnnlocalization.csail.mit.edu/
“Exploring Neural Networks with Activation Atlases” (Carter et al. 2019)- https://distill.pub/2019/activation-atlas/
“Attention Is All You Need” (Vaswani et al. 2017)- https://arxiv.org/abs/1706.03762
“Graph Attention Networks” (Velickovic et al. 2017) — https://arxiv.org/abs/1710.10903
“A-CNN: Annularly Convolutional Neural Networks on Point Clouds” (Komarichev et al. 2017) — https://arxiv.org/abs/1710.10903
“Recurrent Models of Visual Attention” (Mnih et al. 2014) — https://arxiv.org/abs/1710.10903
“A Reinforcement Learning Model of Selective Visual Attention” (Minut, Mahadevan, 2001) — https://arxiv.org/abs/1710.10903
“The REINFORCE Algorithm aka Monte-Carlo Policy Differentiation” (Mcneela, 2018) — https://mcneela.github.io/math/2018/04/18/A-Tutorial-on-the-REINFORCE-Algorithm.html
“ Show, Attend and Tell: Neural Image Caption Generation with Visual Attention” (Xu et al. 2015) — https://arxiv.org/pdf/1502.03044.pdf
“A Gentle Introduction to Calculating the BLEU Score for Text in Python” (Brownlee, 2017) — https://machinelearningmastery.com/calculate-bleu-score-for-text-python/
“Non-local Neural Networks” (Wang et al. 2017) — https://arxiv.org/abs/1711.07971
“A Simple Neural Network Module for Visual Reasoning” (Santoro et al. 2017) — https://arxiv.org/pdf/1706.01427.pdf
“Kinetics dataset” (Google Deepmind, 2017) — https://deepmind.com/research/open-source/kinetics
“A Comprehensive Introduction to Different Types of Convolutions in Deep Learning” (Bai, 2019) — https://towardsdatascience.com/a-comprehensive-introduction-to-different-types-of-convolutions-in-deep-learning-669281e58215
“ Self-Attention Generative Adversarial Networks” (Zhang et al. 2018) — https://arxiv.org/pdf/1805.08318.pdf
“Learn to Pay Attention” (Jetley et al. 2018)” — https://arxiv.org/pdf/1804.02391.pdf
“Neural Machine Translation by Jointly Learning to Align and Translate” (Bahdanau et al. 2015) — https://arxiv.org/pdf/1409.0473.pdf
“Learning Multiple Layers of Features from Tiny Images (CIFAR 10,100 Datasets)” (Krizhevsky, 2009) — https://www.cs.toronto.edu/~kriz/cifar.html
“Weakly Supervised Learning for Computer Vision” (Benenson, Bilen, Uijlings, 2018) — https://hbilen.github.io/wsl-cvpr18.github.io/
“Unsupervised Joint Object Discovery and Segmentation in Internet Images (Object Discovery dataset)” (Rubinstein et al. 2013) — http://people.csail.mit.edu/mrub/ObjectDiscovery/
“Breaking neural networks with adversarial attacks” (Jain, 2019) — https://towardsdatascience.com/breaking-neural-networks-with-adversarial-attacks-f4290a9a45aa
“Generative Adversarial Nets” (Goodfellow et al. 2014) — https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf
“Conditional Image Generation withPixelCNN Decoders” (Oord et al. 2016) — https://arxiv.org/pdf/1606.05328.pdf
“Pixel Recurrent Neural Networks” (Oord et al. 2016) — https://arxiv.org/abs/1601.06759
“Wavenet: A generative model for raw audio” (Oord et al. 2016) — https://arxiv.org/pdf/1609.03499.pdf
“Analyzing Multi-Head Self-Attention:Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned” (Voita et al. 2019) — https://arxiv.org/pdf/1905.09418.pdf
“Image Transformer” (Parmer, Vaswani et al. 2018) — https://arxiv.org/pdf/1802.05751.pdf
